

人們對利用多源檢索數據(如鉆孔、地球物理技術、地質圖和巖石性質)創建高分辨率三維地下地質模型越來越感興趣,以便進行應急管理。然而,要從這些集成的異構數據中獲得有意義的、可解釋的三維地下視圖,需要開發一種新的方法來方便地進行建模后分析。為此,本文提出了一種基于混合集成的自動深度學習方法,用于使用多源數據進行地下地質基巖的三維建模。然后使用植入關節權重數據庫的新型集成隨機自動失活過程對不確定性進行量化。然后,通過使用來自瑞典的激光掃描基巖水平數據創建三維地下地質模型,驗證了自動化過程在捕獲最佳拓撲結構方面的適用性。與智能分位數回歸和傳統地統計學插值算法相比,該方法在三維地下模型的可視化和后期分析方面具有更高的精度。由于使用了集成的多源數據,本文提出的方法和隨后創建的3D模型可以作為地球工程應用的代表性調和。
在地球工程實踐中,對從空間分布的鉆孔中獲取的信息進行適當的匯總,可以促進地下分析和制圖,以支持各種地下項目的決策(例如,[41,52,71])。通常通過在二維截面上顯示的鉆孔數據來確定特定地質單元(如巖石、巖性地層、礦化區)的延伸。然而,在地理模型中,由于不均一性和無法解釋空間分析,從稀疏的垂直約束井眼數據中解釋橫向分布屬性是一個困難的障礙[9,24,43]。因此,描述屬性參數空間分布的檢索結果不僅經常與地質知識相沖突[43],而且在后期操作階段需要不斷更新[71]。因此,為了概念化地下特征的空間格局,需要在3D中開發二維地質模型[9,10,29]。然后可以使用補充的測試數據進行補充,以獲得更準確的推理結果(例如[1,2,3,58,66])。在數學上,三維地質模型表達了地質構造/物體的數字坐標和相關特征,這些特征可以在地球工程現場特征中實際實施(例如,[2,28,31])。這意味著三維地質模型在分析地下利用和城市環境的地下屬性信息方面具有巨大的優勢。然而,由于數據、分辨率和所需細節的多樣性,收集和呈現三維地理空間信息一直是一個挑戰[9,39,58,73]。
為了提高地理空間橫向分布屬性的可解釋性,將不同的合格鉆孔數據與數值算法([11,42]或認知解釋方法[16,24,53,53])相結合已成為一種常見的做法。這種方法導致在觀測點之間進行插值,以納入專家地質知識。在這種觀點下,平面網格的三維插值[67]、曲面網格生成[23]和三角剖分算法[18]被認為是處理離散井眼數據的最合適選擇[1]。然而,這些方法的適用性在當前的地球工程建模方法(例如[27,34,35,49,60])中仍然至關重要,盡管存在與處理時間和處理大數據的局限性相關的一些挑戰。
為了應對大數據的挑戰[17],熟練的人工智能技術(AIT)在淺/深神經學習網絡(SNLNs/DNLNs)、機器學習(ML)、混合模型和進化算法方面的應用已經出現在各種地球工程問題中(例如[1,2,3,32,54,59,73])。基于dnlns模型的三維計算機視覺,由于其特征特征[38],因此比GIS和CAD系統[21,42,72]提供了更有力的工具,已用于地球工程應用[1,2,59,70]。然而,基于深度神經網絡的預測模型的魯棒性應該根據不同的精度性能標準和不確定性量化(UQ)分析來評估(例如,[5,47,61])。
隨著人口密集的大都市地區的增長,利用地下城市規劃來克服與可持續城市和環境法規相關的挑戰,以響應技術和社會經濟需求已經得到強調[12,46]。從地球工程的角度來看,基巖深度(deep to bedrock, DTB),即基巖以上沉積物的厚度,是正確利用地下資源的關鍵因素。在瑞典,有大量的已建成基礎設施(如交通隧道、公路、鐵路),DTB的三維空間分析是一個重要的問題,可以為結構的穩定性提供關鍵的見解[2]。生成足夠精確的三維可視化空間DTB模型不僅有助于解釋稀疏的巖土測量結果,而且還為確定最佳解決方案和風險評估(例如[2,3,24,25,26,64,68])提供了有價值的工具。然而,在地球工程項目中,由于巖土技術的限制(例如,整個區域的獲取、成本、探測之間的距離)所包含的不確定性,制作高分辨率三維空間DTB預測模型不僅需要不同的數據類型組合,而且是一項關鍵任務[1,2,26,64]。
DTB可以使用傳統的地質統計技術生成。然而,復雜問題大地理數據所采用的計算/圖形系統有限[22,65]、非平穩性等技術問題需要擴展隨機函數模型,實際問題的合理解決方案在模型選擇上存在困難,參數估計和不確定性的傳播[19,42,44,57]將增加處理大數據的分析時間和成本[5]。因此,這些技術通常在小規模地區進行[69]。另一方面,在DNLN中,UQ分析是一個相對未被充分探索的話題[5,6,51],從技術上講,它為尋找不同的機會、新的選擇和被忽視的解決方案提供了空間。因此,UQ分析在基于dnn的預測模型中起著關鍵作用,因為錯誤的答案不一定是問題,但它是案例分歧中的一個問題,可以有效地影響優化和決策過程中評估的準確性。隨著AIT技術和代碼開發的出現,這種需求提供了強大的新應用程序,以幫助滿足地球工程師在解決建模障礙方面的要求。
為了克服上述挑戰,開發一種基于dnnn - uq的現代自動化混合方案,以產生足夠精確和高分辨率的3D可視化地下,這是非常有動力的。在本文中,創新性地結合了兩個不同的自動化過程,使用隨機關閉的聯合權重數據庫來跟蹤模型優化和UQ分析。由于嵌入內嵌循環,可以顯著減少超參數調整以獲得最優模型的計算時間。將混合模型作為城市規劃的有利工具,應用于瑞典不同土壤-巖石測深和地球物理調查的644個數據集的地理空間定位。然后,使用單獨提供的75,715個掃描巖石表面數據集對可預測性性能進行控制和評估。與分位數回歸(QR)[14]和地質統計學普通克里格(OK)[62]進行的詳細分析表明,可以繪制高分辨率三維空間預測地下DTB地圖。
如圖1a所示,研究區域位于瑞典西南部,靠近哥德堡。本研究中使用的巖土工程數據是沿B?linge和v
rg
rda之間的E20公路收集的(圖1b)。瑞典交通管理局考慮到目前超速、交通安全和環境等問題,計劃在舊E20附近新建一條高速公路。在靠近B?linge的西段,擬建的高速公路穿過巖石露頭、冰磧、冰川粘土、冰川沉積物和膨脹沉積物。規劃道路沿線基巖以片麻巖為主,閃孔、黑云母等深色礦物含量較高。偉晶巖,一種花崗質層狀巖石,幾乎沿著整條道路被發現。基巖為一般非均質復雜化合物。然而,在路線的終點,基巖變得更加均勻,主要由所謂的v
rg
rda花崗巖組成(?sander, 2015)。本區片麻巖斷裂帶總體呈東西走向。而靠近B?linge斷裂帶則以西北—東南方向為主,靠近v
r
rda斷裂帶則以東北—西南方向為主。裂縫面通常向南傾斜,如果進行巖屑切割,可能會導致穩定性問題(?sander, 2015)。參考圖1b,利用空間地理定位坐標對644個土/巖測深和物探多源數據集進行了表征和編譯。然后將數據隨機分為65%、20%和15%,以提供訓練集、測試集和驗證集。因此,在輸入模型之前,將使用的數據集進行歸一化處理,在[- 1,1]區間內提供相同的比例尺。
圖1
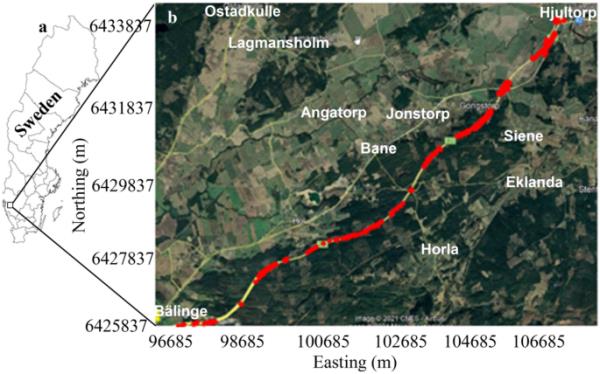
瑞典項目區位置(a)和644個獲取的測試點(紅色)在Google Earth圖像(b)上的地理空間分布疊加
人工智能的概念可以定義為人腦結構的簡化模仿可學習布局,旨在通過嵌入連接處理元素來提高計算能力。與傳統的建模方法相比,基于人工智能的系統有幾個公認的優勢,它們越來越多地用于地球工程應用的計算機視覺領域[1,2,40,50]。DNLNs是AIT的一個子類,它不需要明確地掃描數據以搜索可組合的特征以更快地學習。這意味著深度神經網絡可以成功地處理非結構化數據(不同的格式,如文本、圖片和pdf),并探索人類可能錯過的新的復雜特征[38]。因此,dnl提供了比ML更大的容量來執行特征工程,從而顯著縮短了計算時間。因此,dnln中的UQ分析可以在輸入變量、假設和近似值、測量誤差以及稀疏和不精確數據的背景下進行描述[5]。然而,使用這些技術進行基于價值的判斷的所有不確定性來源可能都無法量化[47]。
如圖2所示,在DNLN的全連接配置中,第k隱層第j個神經元在第n次迭代時,受激活函數f的輸出定義為:
(1)
在那里;Nk表示KTH層中神經元的數量,并表示從神經元接收的求和信號偏移的偏差。
圖2
DNLN架構的簡單配置
然后使用第k個隱藏層中第i個神經元的相應誤差更新權重和偏差,通過以下方法最小化預測誤差:
(2) (3)
在那里;是對的一階導數。和表示動量常數,動量常數決定了過去參數變化對參數空間中當前運動方向的影響,通常在[0.1,1]區間內變化,用于避免更新過程中的不穩定。表示學習率。
然后使用更新后的權值計算整個網絡的總誤差E(t)、預測誤差和第m個輸出層第l個神經元的結果:
(4) (5) (6)
在那里;Dj (t)表示神經元j在第t次迭代時的期望輸出。Y和no分別表示實際輸出和輸出層神經元數量。
如圖3所示,開發了一種混合自動化方法,包括兩個區塊和幾個嵌入的內部嵌套環路,以及用于地下3D建模的開關箱。給定區塊的概述(圖3)已成功地獨立應用于地下水位任務的DTB和UQ分析建模[2,5]。然而,通過內部組合融合兩個具有不同目的的截然不同的自動化概念是一項具有挑戰性的任務。配置混合模型的主要技術新穎之處在于內部集成了兩種不同的自動化方法,使用DNLN和基于集成的結構,使用聯合權重數據庫追求和選擇最精確的拓撲結構。由于DNLN需要足夠的計算能力和學習所需的數據[13],在Block A(圖3)中,該過程監控了各種組合的內部超參數,如表1所示。為了增強社區支持的模塊化管理,從而提高計算能力和優化性能,該過程使用Python和c++進行編碼。參考表1,根據分析的誤差改進[4,25],將捕獲最優DNLN作為用戶自定義選項的隱藏層數設置為3。使用這種方法,在最后一次或每次迭代期間監視的網絡性能可預測性可以檢測到模型何時沒有改進,從而不需要進一步的訓練。參考不同隱藏層數的編譯結果,即神經元數從30個增加到80個,從3個增加到8個,在超過4個隱藏層和40個神經元的模型中,分析誤差沒有改善,因此選擇3個隱藏層和35個神經元。這樣的集成組件允許系統監控內部超參數的不同組合,不僅使學習更快,而且最大限度地減少了陷入局部最小值或過擬合問題的機會[1]。為了防止早期收斂,考慮了兩步終止標準,如果根均方誤差(RMSE)作為第一優先級沒有實現,那么迭代次數(設置為1000)將被替換。因此,大量捕獲的淺層和深層神經網絡,即使具有相似的拓撲結構,但具有不同的超參數,也有助于提高所選模型對新示例的泛化能力[2]。UQ方法確定了模型的校準置信度,因此可以證明由于預測置信度過高或不足而引起的偏差。因此,評估基于深度神經網絡的模型在實際應用之前的可靠性和有效性是一個重要的問題。這意味著,在不考慮UQ的情況下,對基于dnn的模型進行關鍵決策的可預測性評估通常是不可信的。此外,UQ分析是DNLN中相對較少探索的主題,特別是在應用于地球工程應用時,因此涵蓋優化和不確定性估計的自動化雜交模型非常有趣。因此,為了控制所獲得拓撲的穩定性和最優性,UQ使用一種新的基于集成的自動隨機停用權重數據庫(ARDCW)方法進行估計,如Block B所示(圖3)[5]。由于實現了最優拓撲,更新和調整后與處理元素相關的權重以矩陣的形式保存為數據庫,以協調實際結果和預測結果之間的差異,并直接應用于驗證/未標記數據集以進行后續預測。因此,在Block B中,只使用自動化優化后的最終權重數據庫。這意味著去激活方法僅適用于最優拓撲的權重數據庫。隨后,使用關閉權重組件自動重新訓練模型,以監控不同場景下預測輸出的變化。因此,克服了通過不同優化器對復雜拓撲進行多次訓練的計算成本挑戰[1]。
圖3
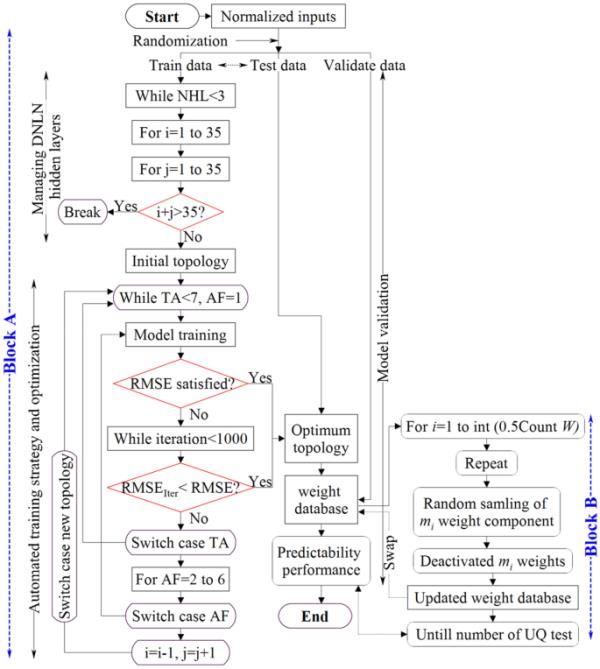
提出了混合布局的自動化方法來捕獲最優拓撲并進行UQ分析
表1常用的超參數選擇最優模型
考慮超參數的組合使用,從2000多個具有不同內部特征的被監測和排序拓撲中識別出最優模型。圖4a顯示了一系列在選定的超參數(表1)下,訓練階段最小RMSE變化的結果。使用這個過程,過度擬合、早期收斂和陷入局部最小值的風險將被最小化,因為即使是相似的拓撲,但具有不同的超參數也會被檢查。當經過一定次數的epoch后準確率沒有提高時,也可以檢測到過度訓練問題[5]。如表1,圖3和圖4(a-d)所示,檢查不同的AF,改變拓撲結構,并監測殘余連接,以確保防止梯度消失。此外,在自動化過程中,保存了每個模型三次運行的最佳結果。參考圖4a,可以選擇QN和Hyt作用下結構為3-20-15-1(輸入變量-隱藏層神經元1-隱藏層神經元2-輸出)的DNLN拓撲為最優。隨后,使用隨機化數據集獲得的拓撲的可預測性如圖4(b-d)所示。
圖4
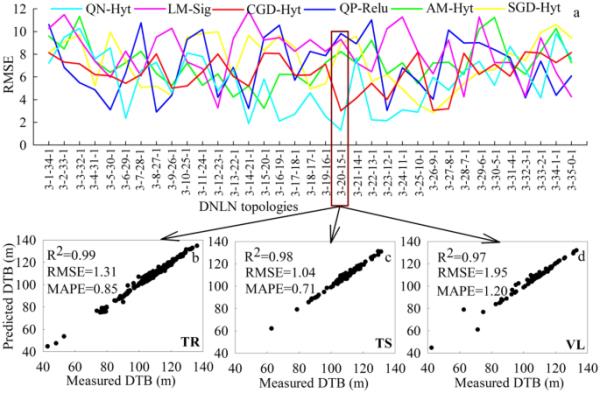
通過RMSE (a)的變化確定預測DTB的最佳拓撲,并使用訓練(b)、測試(c)和驗證數據(d) (TR訓練數據)確定相應的可預測性;TE測試數據;VL驗證數據;平均絕對百分比誤差)
使用ait創建和模擬三維模型是一種很有前途的地下地球工程工具(例如[1,3,71,74])。這是因為傳統方法依賴于專家的知識和經驗來選擇假設、參數和數據插值方法,這些都是主觀的和有限的[51]。
圖5顯示了研究區地下空間DTB分布的分步三維建模與實際掃描數據的對比。然后,可以通過疊加生成的地表和空間掃描DTB來識別巖石露頭,從而獲得具有足夠精度的高分辨率預測3D地下模型,用于地球工程項目。圖5d顯示了使用ARDCW[5]對已實現的最優DNLN拓撲進行預測誤差的UQ分析結果。
圖5
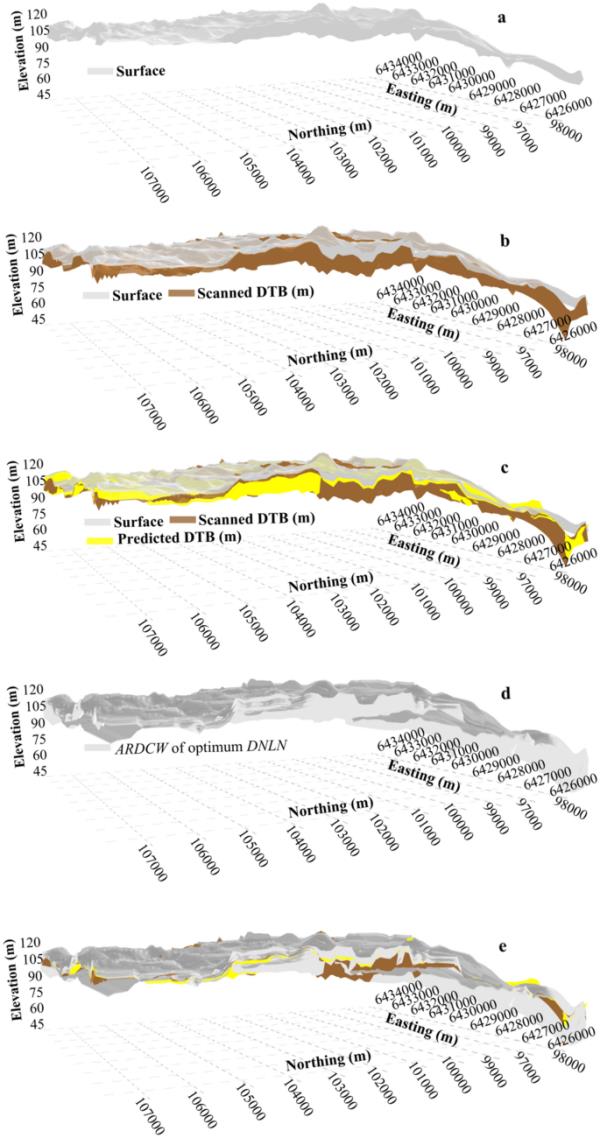
為研究區域創建的三維模型的逐步側視圖,包括a地表,b, c包含掃描和預測DTB的空間分布,d, e使用自動化系統使用ARDCW估計UQ
摘要
1 介紹
2 研究區域和數據來源
3.模型開發過程
4 討論和結果驗證
5 有限公司
ncluding講話
數據和材料的可用性
代碼的可用性
參考文獻
致謝
作者信息
道德聲明
搜索
導航
#####
3D數字模型可以改善工程師、施工人員和客戶之間的溝通,例如競標、成本分析和列出所需資源。由于3D模型的成功取決于地下復雜性的可視化分辨率,因此在實踐中和使用前應根據不同的精度性能指標仔細評估。在本研究中,通過比較QR和傳統地質統計普通克里格(OK)的不同分析指標,對生成的三維模型進行了討論。然而,由于AIT的強大計算能力,異常值的預測比傳統技術更準確,因此可以預期更好的性能。除了隨機驗證數據外,還使用激光雷達在研究區東北部Jonstorp和Hjultorp之間的幾個區域進行激光掃描獲得的75,715個真實基巖面(圖1)來討論該方法的性能。然后可以將預測的基巖面與掃描的基巖面進行比較,以評估模型的性能。
在傳統的地統計學插值算法中,當變異函數已知時,OK可以用于空間估計[62]。然而,由于使用插值,OK只能預測觀測范圍內的DTB值,而QR和DNLN由于回歸和考慮最小平方誤差,甚至可以預測制表域之外的值。從數學的角度來看,可以得到(n + 1)個DTB點的一個n階多項式,它精確地通過所有(n + 1)個數據。這就是為什么在訓練過程中,不同變異函數作用下的OK顯示出較高的R2(表2)的主要原因。因此,在訓練過程中,在觀測域內,回歸可能不如插值DTB準確,但在觀測值以下和之外的范圍內,可以提供更好的預測。這合理地解釋了為什么OK中預測數據的R2變化顯著(表2)。此外,由于OK在統計上包含了多個可以被數據證明的參數,因此所獲得的結果可以歸因于過擬合[20],而變異函數參數的可變性導致了基于同一數據集的不同預測。這意味著受大數據影響的OK不能很好地泛化,并且預測的新值隨后提供了對特定數據集的密切響應。
表2好吧結果經過8 ~ 14次滯后和不同的變異函數
此外,為了進行適當的評估,不應該使用整個數據集訓練模型,因為這會導致太多的學習和飽和[15,56]。這種訓練的結果是在輸入數據中捕獲更多的噪聲,這些噪聲會引起模型的劇烈波動,從而不能代表預期的趨勢[1]。參考圖6a,由于不對稱加權處理,使用QR預測掃描的DTB受數據集中異常值的影響比OK小(圖6b)。然而,QR中的參數估計比高斯或廣義回歸更難。圖6c表明,與全變分正則化調整后的QR和OK相比,DNLN具有足夠的靈活性,可以更準確地預測非線性模式,強調了該方法對于掃描DTB數據的實用性。
圖6
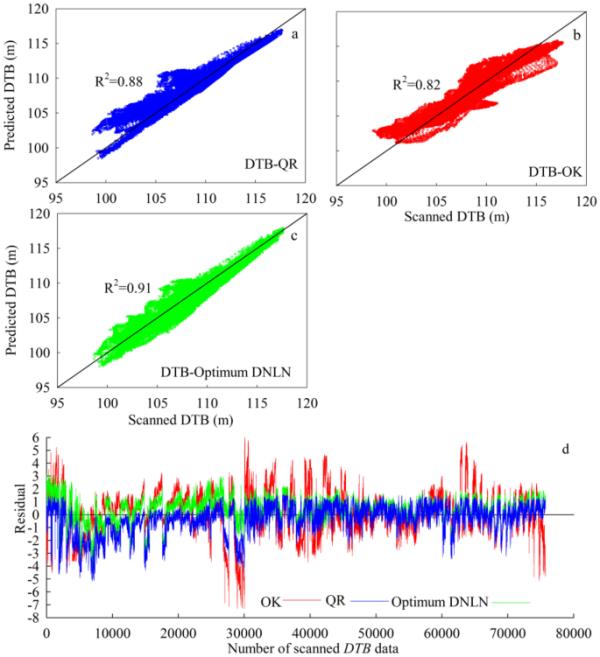
可預測性的QR, b OK, c最優DNLN,和d計算殘差掃描DTB
根據估計與檢驗理論[33],可以使用殘差圖來分析非正態分布,特別是對不適當指定的模型或誤差方差的非均勻性。此外,計算殘差的過小值提供了足夠穩定的模式,從而允許有效的統計推斷[33]。圖6d顯示了應用模型下掃描DTB和預測DTB之間殘差的隨機模式,理想情況下,結果應該是小而非結構化的,其中觀察到的大值是由異常值引起的。因此,殘差代表驗證數據中未被模型解釋的部分。從這個角度來看,圖6d中顯示的圖是一個控制圖,用于確定是否應該繼續/調整過程以達到所需的質量。
預測模型在分析上依賴于應用技術的精度和準確性。根據中心極限定理,預測模型的方差本質上是對不同人群的方差進行比較,以檢驗相等的假設。由于掃描的DTB有已知的標準偏差(SD),因此結果更接近的模型更容易被接受。這意味著所實現方法的可接受性因此可以根據觀測誤差相對于定義的總允許誤差(TAE)的大小來判斷,如圖7[36]所示。因此,對于與訓練和掃描DTB總量相對應的76,359個數據集,TAE的值為6.811。利用DNLN、OK和QR預測DTB的TAE分別為6.49、5.01和6.07。這些值指定了在不使測試結果的解釋無效的情況下允許的測定的不精確和偏差組合的最大誤差量。因此,與計算殘差相比(圖6d), OK已經超過TAE,這可以解釋為該模型在處理大數據時存在不穩定性。利用QR、OK和最優DNLN計算殘差的標準差分別為1.15、1.68和0.98來支持TAE的精度。
圖7
定義TAE (SD標準差,SE標準誤差)
根據Akaike的信息準則(AIC)[7]對模型附加項進行處罰,降低RMSE和增加R2的附加變量不適合模型的選擇。目標是找到最小化AIC的模型,回歸可以計算為:
(7)
在那里;P為變量數,n為記錄數,多k個額外變量的模型被罰2 k。對于相似的訓練數據,AIC是預測誤差的估計器,因此可以代表每個模型的質量[55]。這意味著AIC估計給定模型丟失的信息的相對量,其中模型丟失的信息越少,該模型的質量越高。這意味著AIC處理擬合質量和模型簡單性之間的權衡,導致過擬合風險和欠擬合風險[8]。根據式(7)中的RSS, OK、QR和最優DNLN的殘差平方和分別為160,000、110,899和81,984。從這個角度來看,OK、QR和最優DNLN模型的AIC (Eq. 7)的第二個代數項分別為24,602、12,549和2,615。因此,OK在訓練和驗證中獲得的高R2和低RMSE(表3)不能導致比QR和最優DNLN更好的性能。
表3應用統計誤差標準對e評估和比較所采用的模型
在地球工程背景下,統計分析是可靠解釋實驗結果的重要工具。此外,基于數據的決策和意見的重要性日益增加,可以關鍵地評估分析的質量,因此可以使用統計誤差度量來降低決策中的風險。然而,使用單一度量的統計分析可能會快速而簡單地理解,但在復雜的地球工程問題中,提供的解釋圖像分辨率非常低。這是因為度量不同于損失函數。因此,對于統計指標的合理結論,往往需要對多個指標進行分析,使其結果相互印證。例如,由于決定系數(R2)不能揭示回歸模型的正確性和因果關系的信息,因此需要補充其他標準。另外,也不能說明回歸模型的正確性。R2最常見的解釋是回歸模型與觀測數據的擬合程度,因此DNLN、QR和OK中的0.91、0.88和0.82表明,從75,715個數據中,共有68,901、66,629和62,086個數據被擬合到回歸模型中(表3)。因此,與QR和OK相比,DNLN模型提供了3.3%和9.9%的改進。隨后,RMSE為大錯誤賦予了相對較高的權重,因此在特別不希望出現大錯誤時非常有用。使用平均絕對百分比誤差(MAPE),可以直觀地解釋誤差的程度或重要性。MAPE致力于相對誤差的獨立性,從而可以比較不同尺度數據之間的預測精度。因此,結合RMSE和MAPE提供了一個二次損失函數,也可以量化預測模型中的不確定性。因此,使用一致性指數(IA)[63],給予誤差適當的權重,而不是通過它們的平方值來膨脹。方差計算(VAF)衡量模型和實際數據在每個運行條件下的差異,通常用于驗證輸出結果的正確性,從而顯示數據的可變性有多少可以用擬合的回歸模型來解釋。然后對生成的3D模型MAPE、VAF、IA、R2和RMSE以及一般標準差(GSD)和差比(DR)的結果進行評估,結果如表3所示。因此,MAPE、DR、GSD和RMSE越低,VAF、IA和R2越高,模型的性能越好。
在地下地球工程應用中,三維建模在可視化詳細地質特征方面的能力正在逐步提高(例如[9,23,27,49])。這種3D預測地理空間模型可以根據可用的特征因素顯示數字化的幾何或拓撲對象,從而可以在與完成項目的視圖非常相似的圖像中捕捉建筑物和基礎設施的復雜性。因此,3D模型可以幫助地球工程師選擇更合適的結構元素,并幫助交付更安全的項目設計。適當調整的DNLN可以很容易地與新數據相適應,以提高診斷性能和計算機視覺修改。它還可以提供未來獲得的數據,以反映更多的地下特征細節。考慮到這一點,在創建空間3D視圖時,應用模型的可預測性與受75,715掃描DTB的區域輪廓中的殘余輪廓進行了比較,并在圖8中給出了。可以觀察到,DNLN、QR和OK的實測/掃描基巖面與預測基巖面的殘差不同。DNLN方法估計的殘差區間最窄[-3.5,3.5 m],表明預測模型比其他方法更準確。
圖8
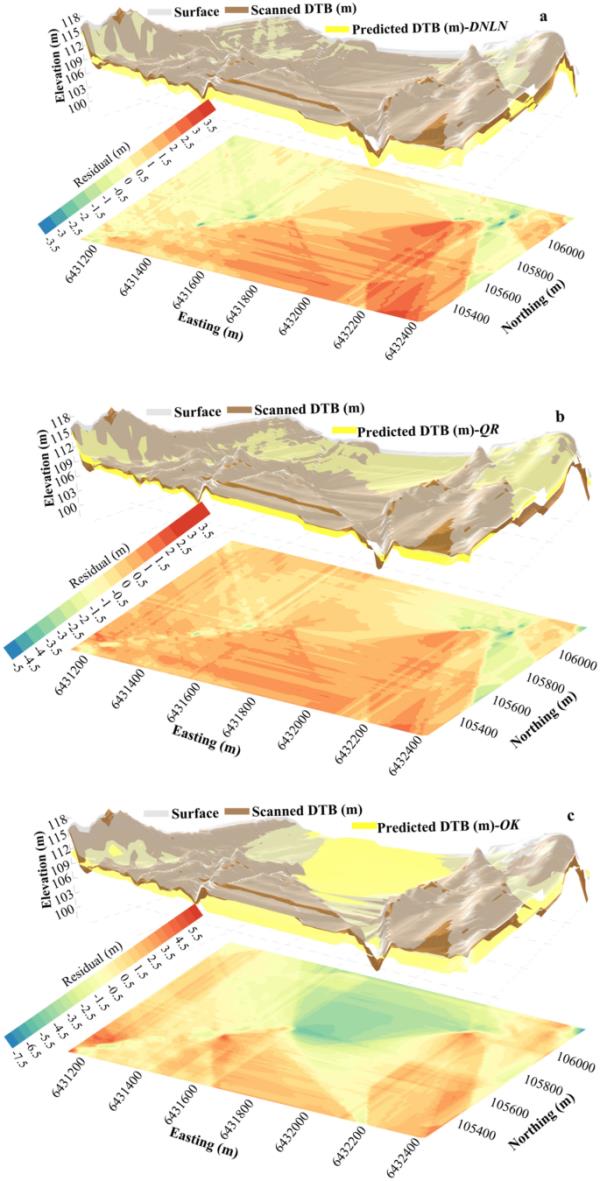
將預測模型和掃描的DTB數據結合使用應用方法生成的3D模型的俯視圖,以獲得最佳DNLN, b QR和c OK
4.3.1 估計UQ掃描間隔防曬霜
盡管在地球工程問題中有各種3D建議的高級分析方法(例如,[2,48,72]),但由于應用計算建模技術中使用的假設和傳播誤差所分析的UQ可能會產生顯著差異。此外,應該考慮從單一研究中進行推廣的相關問題,難以獲得適當的度量,以及與確定模型表示的最高準確性相關的問題[5]。在這種情況下,預測區間(PI)為單個估計的UQ提供了一個指標。PI比點估計有優勢,因為它考慮了數據的可變性,為觀測值提供了一個“合理”的范圍[45]。因此,PI必須考慮到預測總體均值的不確定性和個體值的隨機變化[37],因此它總是比置信區間更寬。這意味著,當統計數據不能用于解釋未來的數據時,可以使用基于已知總體數據的PI來估計即將到來的觀測值的UQ。使用PI的主要優點之一是,它給出了一個可能的權重范圍,因此建模者可以了解預測的權重可能有多準確[30]。圖9給出了使用ARDCW-DNLN、QR和OK掃描DTB區域的90% PI水平估計的UQ間隔。每個2m間隔的百分比(圖9)反映在表4中。根據PI計算,在[0.6 m, 5.2 m]區間內估計UQ的ARDCW-DNLN比OK和QR的區間更窄,結果更簡潔,精度更高。這意味著OK、QR和ARDCW-DNLN的偏差和差異可以通過比較估計的UQ來解釋。分類UQ區間的分布(圖9)可以識別出具有較高不確定性的子區域,從而減少對更多數據的需求,并突出其相應的原位測試的適用性。
圖9
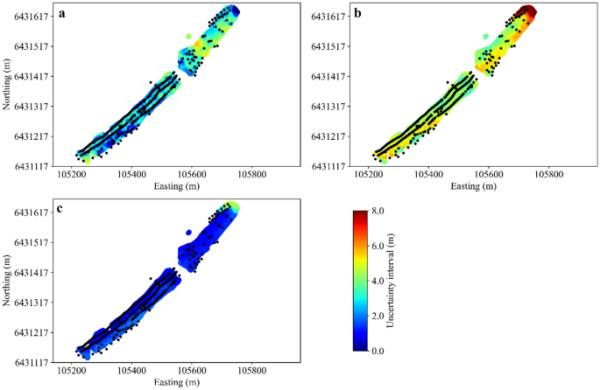
研究區域概述,顯示了在90% PI水平下對OK, b和c最佳DNLN應用方法的比較UQ分析
表4比較模型掃描數據的不確定性區間統計
在3D建模的背景下,提出并開發了一種先進的計算機視覺混合自動dnnn - uq框架,用于使用瑞典的多源地理數據進行DTB分析。為了驗證技術進步,利用75,715個掃描的DTB,將捕獲的最優DNLN在完成任務和產生結果方面的結果與QR和OK進行比較,以提供更好的解釋,并為后期建模分析提供便利。根據計算得到的TAE,預測DTB中OK的殘差超標是由于該模型在處理大數據時的不穩定性。在AIC方面,研究表明,在OK的訓練和驗證中,高達到的R2和低RMSE并不會導致比QR和最優DNLN更好的性能。使用不同統計指標的應用模型的比較也表明,DNLN比QR和OK提供更好的結果。為掃描的DTB創建了90% PI的3D可視化地圖,顯示使用ARDCW-DNLN在[0.6,5.2]范圍內較窄的UQ估計,因此精度更高。
所呈現的3D模型可以改善更多結構元素的視覺分析,從而更好地了解項目所涉及的自然和人為方面,從而導致更安全的設計過程。所呈現的模型的數字靈活性允許添加基礎設施的坐標來修改計劃中的不一致性,而不需要藍圖。然后,這將為立即解決工程難題提供更多適用的解決方案提供機會。使用3D模型還可以增強投標流程,并使承包商受益于自動化智能建模,從而提高施工質量,降低施工成本。經過調整的3D模型不僅加快了設計過程,而且使地球工程師和決策者能夠嘗試不同的想法,并在潛在的設計問題成為實際問題之前識別出潛在的設計問題。這意味著3D建模在施工中可以把工作的所有階段放在一起,并提供完成項目的現實畫面。
下載原文檔:https://link.springer.com/content/pdf/10.1007/s00366-023-01852-5.pdf