

一種新的人工智能(AI)模型剛剛在一項旨在衡量“一般智力”的測試中取得了與人類相當的成績。
12月20日,OpenAI的o3系統(tǒng)在ARC-AGI基準測試中得分為85%,遠高于此前人工智能的最佳得分55%,與人類的平均得分相當。它在一次非常困難的數學測試中也取得了很好的成績。
創(chuàng)造通用人工智能(AGI)是所有主要人工智能研究實驗室的既定目標。乍一看,OpenAI似乎至少朝著這個目標邁出了重要的一步。
盡管懷疑依然存在,但許多人工智能研究人員和開發(fā)人員感到有些事情發(fā)生了變化。對許多人來說,人工智能的前景現在似乎比預期的更真實、更緊迫、更接近。他們是對的嗎?
要理解o3結果意味著什么,您需要了解ARC-AGI測試的全部內容。用技術術語來說,這是對人工智能系統(tǒng)適應新事物的“樣本效率”的測試——系統(tǒng)需要看到多少個新情況的例子才能弄清楚它是如何工作的。
像ChatGPT (GPT-4)這樣的人工智能系統(tǒng)不是很有效。它在數以百萬計的人類文本樣本上進行了“訓練”,構建了關于最可能的單詞組合的概率“規(guī)則”。
其結果是在普通任務中非常出色。它不擅長處理不常見的任務,因為關于這些任務的數據(樣本)較少。

除非人工智能系統(tǒng)能夠從少量的例子中學習并適應更高的樣本效率,否則它們只會被用于非常重復的工作和偶爾失敗是可以容忍的工作。
從有限的數據樣本中準確地解決以前未知或新問題的能力被稱為泛化能力。它被廣泛認為是智力的必要甚至基本要素。
ARC-AGI基準測試使用像下面這樣的小網格正方形問題來測試樣本的有效適應性。人工智能需要找出將左邊的網格變成右邊網格的模式。

每個問題給出三個例子來學習。然后,人工智能系統(tǒng)需要找出從這三個例子“概括”到第四個例子的規(guī)則。
這些很像智商測試有時你可能記得在學校。
我們不知道OpenAI是如何做到的,但結果表明,o3模型具有很強的適應性。從幾個例子中,它發(fā)現了可以推廣的規(guī)則。
為了找出一個模式,我們不應該做任何不必要的假設,或者比我們真正需要的更具體。從理論上講,如果你能找出“最弱”的規(guī)則,那么你就能最大限度地提高自己適應新情況的能力。
最弱規(guī)則是什么意思?技術定義很復雜,但較弱的規(guī)則通常可以用更簡單的語句來描述。
在上面的例子中,這個規(guī)則的簡單英語表達可能是這樣的:“任何有突出線的形狀都會移動到該線的末端,并‘覆蓋’與之重疊的任何其他形狀。”
雖然我們不知道OpenAI是如何實現這個結果的,但他們似乎不太可能故意優(yōu)化o3系統(tǒng)來尋找弱規(guī)則。然而,要想在ARC-AGI任務中取得成功,它必須找到它們。
我們確實知道OpenAI從o3模型的通用版本開始(它與大多數其他模型不同,因為它可以花更多的時間“思考”難題),然后專門為ARC-AGI測試訓練它。
法國人工智能研究人員Francois Chollet設計了這個基準,他認為o3會通過不同的“思維鏈”來描述解決任務的步驟。然后,它會根據一些松散定義的規(guī)則或“啟發(fā)式”選擇“最佳”。
這與b谷歌的AlphaGo系統(tǒng)通過搜索不同可能的走法序列來擊敗世界圍棋冠軍的方式“沒有什么不同”。
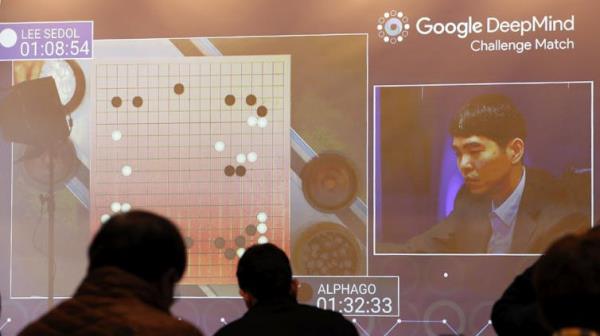
你可以把這些思維鏈想象成適合這些例子的程序。當然,如果它像圍棋AI,那么它就需要一個啟發(fā)式或寬松的規(guī)則來決定哪個程序是最好的。
可能會生成數千個不同的看似同樣有效的程序。這個啟發(fā)式可以是“選擇最弱的”或“選擇最簡單的”。
然而,如果它像AlphaGo那樣,那么他們只是讓人工智能創(chuàng)造了一個啟發(fā)式。這就是AlphaGo的過程。谷歌訓練了一個模型來評估不同的動作序列是好是壞。
接下來的問題是,這真的更接近AGI嗎?如果這就是o3的工作原理,那么底層模型可能不會比以前的模型好多少。
模型從語言中學習的概念可能不再比以前更適合泛化。相反,我們可能只是看到了一個更普遍的“思維鏈”,通過額外的訓練步驟找到了一個專門針對這個測試的啟發(fā)式。一如既往,檢驗將在布丁中。
幾乎關于o3的一切都是未知的。OpenAI只向一些媒體披露了一些信息,并向少數研究人員、實驗室和人工智能安全機構進行了早期測試。
真正了解o3的潛力將需要廣泛的工作,包括評估、了解其能力的分布、失敗的頻率和成功的頻率。
當o3最終釋放時,我們將更好地了解它是否與普通人一樣具有適應能力。
如果是這樣,它可能會產生巨大的、革命性的經濟影響,開啟一個自我完善的智能加速發(fā)展的新時代。我們將需要為AGI本身制定新的基準,并認真考慮應該如何治理它。
如果沒有,那么這仍然是一個令人印象深刻的結果。然而,日常生活將保持不變。


